What is Machine Learning Operations (MLOps)?
Everyone is talking about machine learning. Depending on who is speaking, machine learning (or ML) is an incredible tool that we’ve barely scratched the surface of, or it’s a new killer of unique human worth. ML-generated code is either revolutionary or unusable. ML-generated text and images are either exciting or horrifying for authors and illustrators.

If you ask a ML engineer, you might get a heavy sigh or a rant about their workweek. Machine learning models are complicated. Every use case has a long list of challenges at every stage, from concept to training to deployment.
Existing DevOps strategies, which help businesses streamline software development don’t always apply. Machine learning operations, or MLOps, follows the spirit of DevOps. It helps businesses use ML efficiently and reliably.
MLOps vs DevOps
If you’re already familiar with the concept of DevOps, you may think that MLOps is just DevOps for machine learning. While the concept and goals are similar, the details are significantly different.
If DevOps is a set of practices for building a traditional house, MLOps is the process for building a house on Mars. The builders still need to plan the basics: architecture, utilities, and labor. However, they also need critical input and feedback from experts in space logistics and the Martian environment. They need to get the right materials to Mars, plus they must ensure that the house can withstand the harsh Martian conditions.
While MLOps and DevOps both care about scalability and reproducibility, their scale, complexity, and methods can be significantly different.
Machine Learning: The Short Version
It’s hard to understand MLOps without knowing what machine learning models are and how they are created. In a nutshell, an ML model is an algorithm with a goal that can learn and adapt to reach that goal based on data.
Imagine a pizza restaurant franchise that wants to use ML to sell more pizza. The team responsible for this project might follow these steps:
- Gather data that they think will help the model learn
- Study the data to understand how the model should use it
- Prepare the data so that a computer can read it all easily
- Create the model, giving it a goal and telling it how to use the datasets
- Train the model by giving it test data and letting it run
- Evaluate the model to find errors and optimize model performance
- Deploy the model to active use
- Monitor the model to make sure it continues to work as expected
The team wants to make an ML model that suggests discounts, coupons, and other promotions. They collect and prepare sales data, labeling it so the model can read it. Designed with maximum profits as its goal, the model trains on the sales data. After training, the team evaluates the model performance, tweaks the model, and retrains the model. When model training is done, they deploy the model to a production environment. The team names it “Pizzatron.” Pizzatron runs on current sales data and sends promotion recommendations to store owners.
Sure that’s a lot of steps. But overall, it’s simple, right?
Machine Learning is Not Simple
Wrong. Every stage of the ML development pipeline is rife with complications, even in our simplified Pizzatron example. For starters, the “team” in the example is often three or more teams in reality. You need data scientists to do a competent analysis. ML engineers are experts at creating ML systems. Software engineering teams collaborate on model development and data preparation.
Pizzatron also needs a software application to run in. Pizzatron is the brain, but software engineers need to create an app “body” for it to interact with the world. Deploying and monitoring Pizzatron’s brain/body combination involves IT and operations.
Even if we assume that everyone involved does their job well, there are bound to be mistakes. What if the initial metrics had a flaw that made Pizzatron “learn” that pineapple-and-anchovy pizza is a big seller at Christmas? What if the designers didn’t account for available materials, so Pizzatron often promotes out-of-stock ingredients? If Pizzatron was developed using data from the United States, will it know how to behave for franchises in Italy and Japan?
Pizzatron clearly can’t be left to its own devices. Like an insecure friend, it requires constant validation. Any problems send Pizzatron right back to the development teams, who must go through the development steps. Again. Like a robot assassin from the future, ML models can come back, again and again, to cause trouble for their creators.
MLOps Makes it Better
If these teams are going to do complicated work together on a regular basis, they need a process. They need automation, defined stages, handoffs, and workflows. This is exactly the structure that MLOps aims to provide. As explained by the authors of ml-ops.org:
“With [MLOps], we want to provide an end-to-end machine learning development process to design, build, and manage reproducible, testable, and evolvable ML-powered software.”
MLOps gives developers, machine learning engineers, and data scientists equal stake in the ML pipeline. It’s a pushing back against the chaos that can ensue when these teams work in isolation.
Like any process, the specifics of MLOps can look different depending on who’s talking and where it’s being implemented. You can also get very granular when talking about the MLOps process. At a high level, though, MLOps practices break down the machine learning workflow into three stages:
- Data Engineering: Gathering and preparing datasets (the data pipeline).
- ML Model Engineering: Training the model and making the model available for usage.
- Code Engineering: Actually integrating the model into a software product.
For a more detailed description of the machine learning lifecycle and the smaller stages within it, check out the Machine Learning Workflow page from ml-ops.org.
Do I Need MLOps?
If your organization—large or small—is trying to integrate ML models into other software, you need to implement MLOps practices. Otherwise, you’re setting yourself up for failure (or at the very least, you’re setting yourself up to struggle).
Think back to Pizzatron. In that example, Pizzatron did get created. The pizza company got a usable software product and a return on their investment. The following months, however, were a nightmare for the Pizzatron development and maintenance teams. They expected to release Pizzatron and move on to other work; instead, they found themselves putting out fires, fixing bugs, retraining the model, and struggling to work together efficiently.
If you’re putting machine learning at the core of important work, start thinking about what your MLOps implementation will look like as early as possible. However, if you’re tinkering with machine learning models, using them as a proof-of-concept, or working solo, a detailed MLOps process is probably not necessary. It’s primarily to help multiple teams efficiently integrate ML models and process automation into software development and delivery pipelines.
How To Implement MLOps
We’ve established that MLOps is about finding effective ways to manage complex work. It’s only natural that implementing a strong MLOps process is, in itself, a significant undertaking. There are two primary components you’ll need to consider: the process definition and the tooling.
Defining MLOps Processes
First, identify precisely what MLOps will look like for your teams. Create a process document that outlines the major stages of your MLOps strategy. Each major stage has its own internal processes. Drill down at least one level and define ownership, handoffs, and triggers within each major stage.
You don’t have to start from scratch. Guidelines like CRISP-ML (Q) are a great place to start.
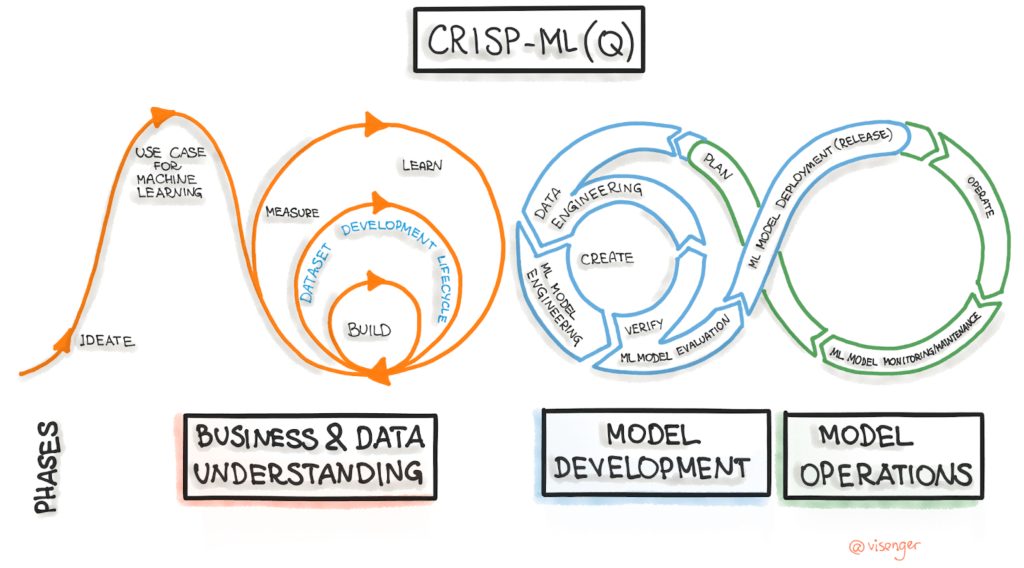
CRISP-ML (Q) breaks every stage of the MLOps lifecycle into tasks for you. These tasks aren’t all simple—”feature selection” isn’t quick or easy—but they’re much more actionable than the stages themselves. This task breakdown table can get you rolling.
Picking MLOps Tools
There’s no single software or tool for MLOps. You’ll need a tech stack: multiple pieces that build on each other. Templates, guides, and other helpful materials are ready to help your Pizzatron be the best version of itself.
The following template is slightly edited from its original source. Either one is a great place to start!
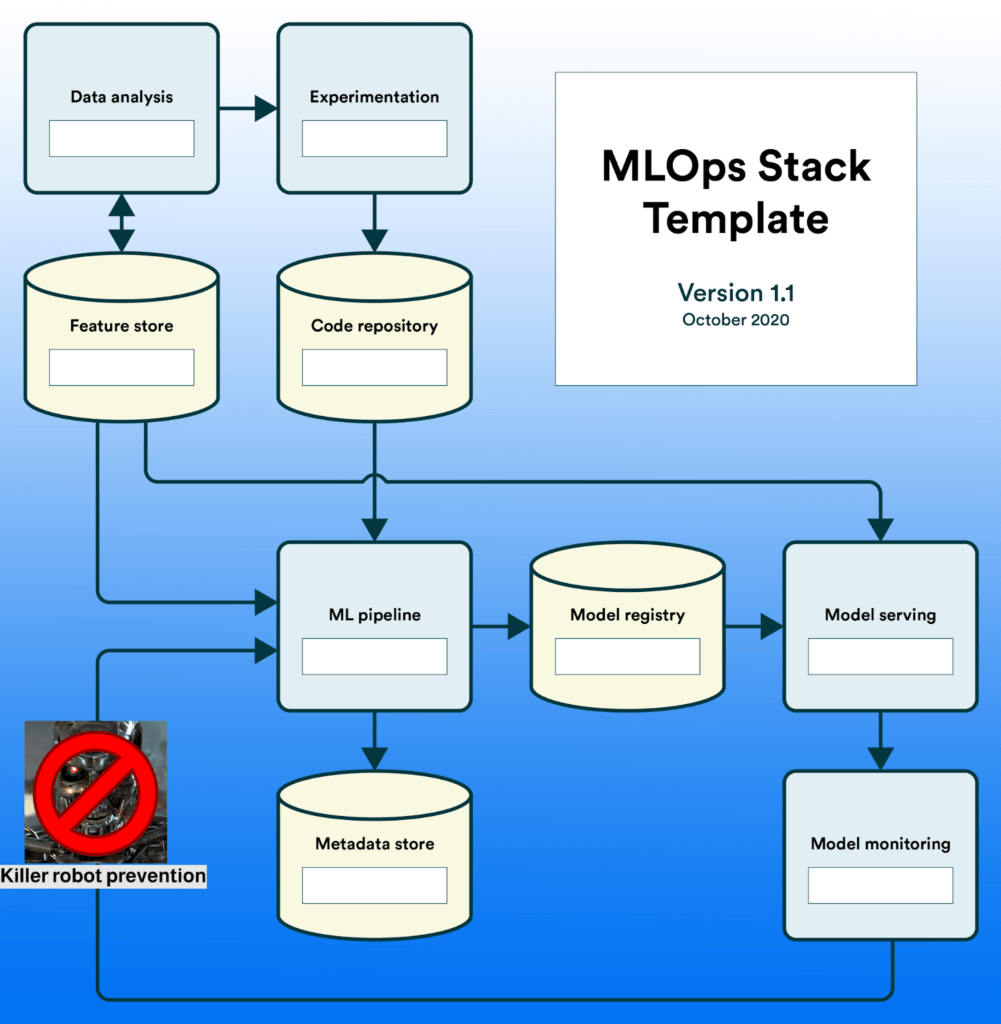
For more resources on finding your MLOps stack, check out the State of MLOps guide. Reviews are a great source of information as well: check out popular MLOps tools to help find the right fit for you.
Conclusion and More Resources
AI and machine learning automation are disrupting everything. The field is still developing, but there’s no reason to expect it to go away. For better or for worse, machine learning models are going to become more and more impactful on the world as we know it.
If you want to integrate ML models into your business, you’re not going to get far without MLOps. If you’ve already started without MLOps, you’re setting yourself up for pain down the road. Don’t wait! Use the available resources. Hammer out a strategy. Fix Pizzatron before it starts recommending that you sell BBQ chicken pizza at your franchises in Italy.
If you’re a complete beginner, you owe it to yourself to at least play with the technology. OpenAI’s playground lets you experiment with ML-generated text for free.
Researching the right product for your machine learning projects can be hard. User reviews can help! Check out reviews for tools that fit in the MLOps stack:
Whatever you do, please don’t make an AI that can write snarky blog posts. I have a family.